
type
Post
status
Published
date
Dec 10, 2023
slug
simple-image-search-engine
summary
tags
AIGC
ChatGPT
必看精选
category
AIGC
icon
password
一、技术方案
一)概览
我们都知道搜索引擎「百度」,「谷歌」可以搜索互联网上的所有文字内容。
搜索引擎对结构化的数据可以识别的非常精准,但是对于非结构化的数据,比如图片,视频,音频却无能为力。
下面这个百度搜索出的图片也是根据图片下面的文字构建的索引,是搜不出图片内的信息的。比如我是个自媒体作者想要引用电影中某个片段,直接用传统搜索引擎完全不行。
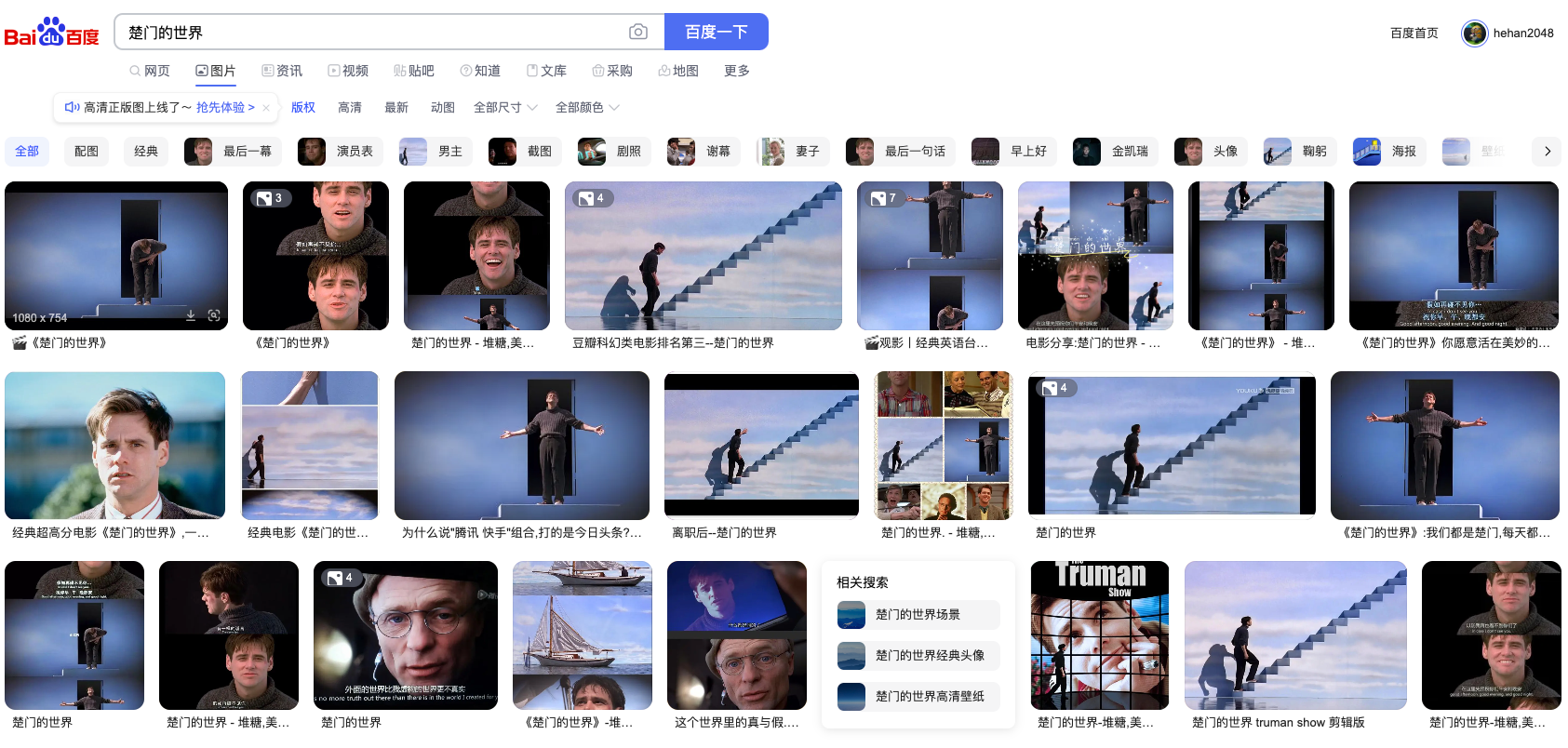
AI时代这里就需要新一代的搜索引擎了。Embedding登场,它可以把所有非结构化数据统一转化为向量,进行向量搜索进行包含语义的查找。
关于什么是RAG和Embedding就不赘述了,之前这篇讲的很详细:https://mp.weixin.qq.com/s/Onn5AiwZBenvPHxIyYoIXg
RAG搜索引擎公式:
语料+EmbeddingModel+向量库+LLM(可选)=搜索引擎
图片文件+图片EmbeddingModel+向量库=图片搜索引擎
视频文件+视频EmbeddingModel+向量库=视频搜索引擎
音乐文件+音乐EmbeddingModel+向量库=音乐搜索引擎
其他垂直行业,比如人脸识别,专利文件,病毒特征,只要训练好对应的EmbeddingModel都可以实对应的搜索引擎。
本次就采用上述的技术方案来完成图片搜索引擎的功能。
拆分成下面几步:选型EmbeddingModel,选型向量库,代码编写,代码示例。
二)Embedding Model选型
Embedding 是一个浮点数向量(列表)。两个向量之间的距离测量它们的相关性。较小的距离表示高相关性,较大的距离表示低相关性。
简单来说就是把所有非结构化数据转化成可以让计算机理解的有语义的数据。
图片Embedding,只会调用openai接口可搞不定了,需要本地运行模型了。这就不得不了解huggingface这个神器了。
huggingface图片分类相关模型:https://huggingface.co/models?pipeline_tag=zero-shot-image-classification
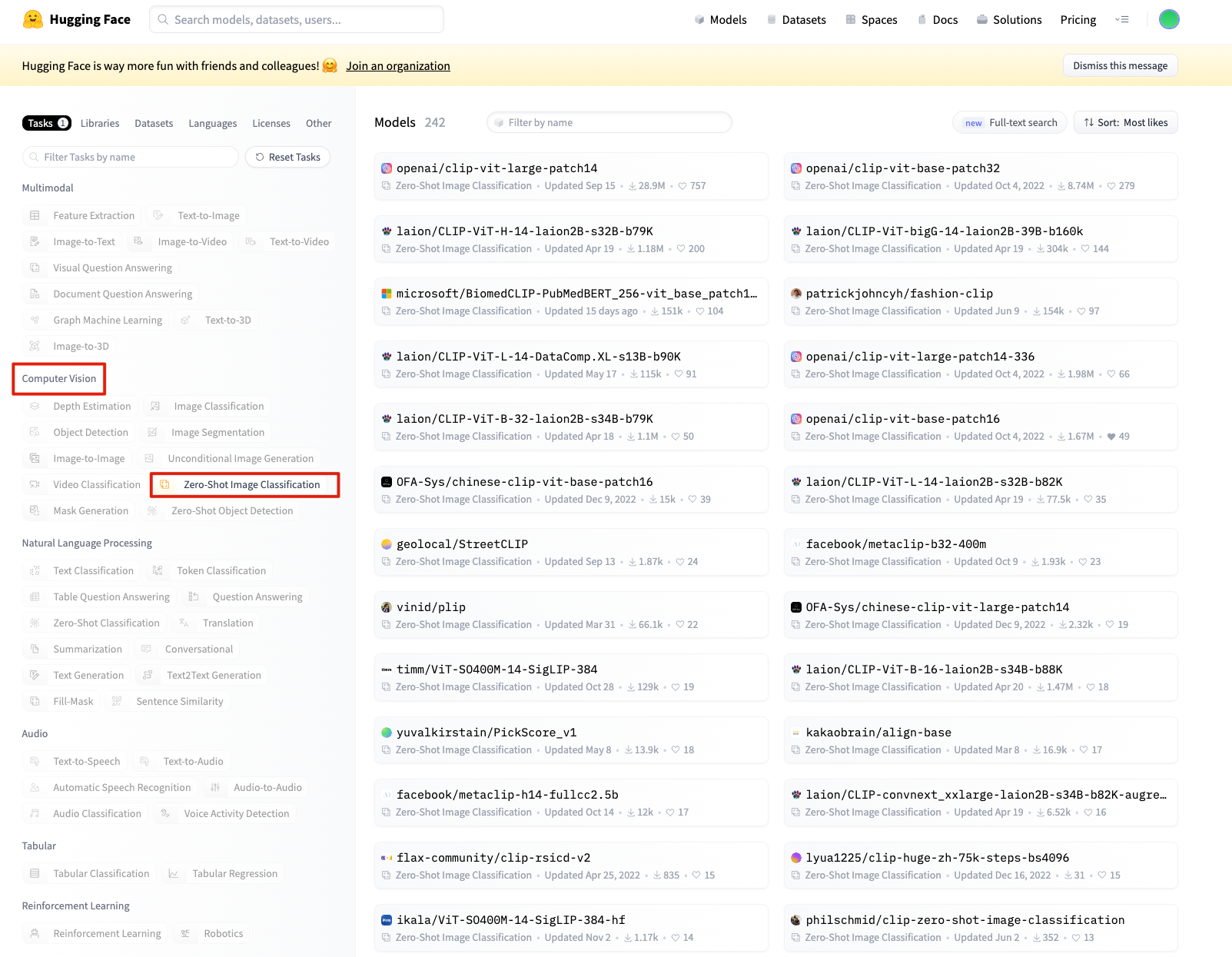
我们还是用老大哥openai的
clip模型试试水。暂时就用最新的,且资源占用不太多的openai/clip-vit-base-patch16。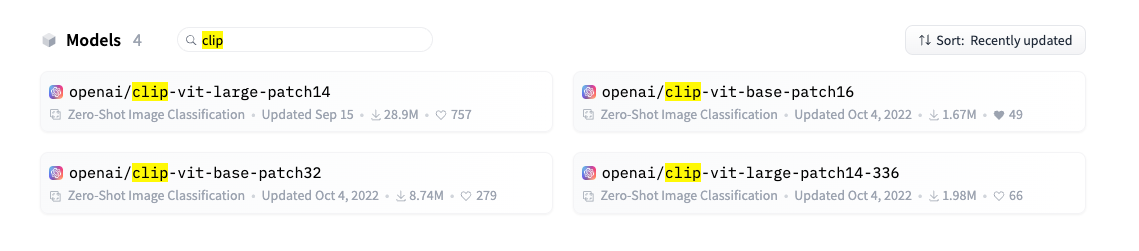
三)向量库技术选型
向量数据库简单来说就是用来存储向量,查询向量的数据库。
1.专用向量数据库
这些数据库从一开始就设计用于处理和检索向量数据,专门为高效的向量搜索和机器学习应用优化。
Milvus
优点: 高效的向量检索,适合大规模数据集。
缺点: 相对较新,社区和资源可能不如成熟的传统数据库丰富。
Weaviate
优点: 支持图结构和自然语言理解,适用于复杂查询。
缺点: 作为新兴技术,可能存在稳定性和成熟度方面的问题。
2.传统数据库的向量扩展
这些是传统数据库,通过扩展或插件支持向量数据的存储和检索。
Elasticsearch
优点: 强大的全文搜索功能,大型社区支持。
缺点: 向量搜索可能不如专用向量数据库那么高效。
PostgreSQL (使用PGVector或其他向量扩展)
优点: 结合了传统的关系数据库强大功能和向量搜索。
缺点: 向量搜索的性能和优化可能不及专用向量数据库。
Redis
优点: Redis是一种非常流行的开源内存数据结构存储系统,它以其高性能和灵活性而闻名。Redis通过模块如RedisAI和RedisVector支持向量数据,这使得它能够进行高速向量计算和近似最近邻(ANN)搜索,非常适合实时应用。
缺点: 由于Redis主要是作为内存数据库,大规模的向量数据集可能会受到内存大小的限制。此外,它在处理大量复杂的向量操作方面可能不如专用向量数据库那样高效。
3. 向量库的云服务
这些服务提供了向量数据处理和搜索的云解决方案,通常易于扩展和维护。
Pinecone
优点: 易于扩展,无需管理基础设施,适合快速部署。
缺点: 依赖于云提供商,可能存在成本和数据迁移方面的考虑。
Amazon Elasticsearch Service
优点: 完全托管,与AWS生态系统紧密集成。
缺点: 可能涉及较高成本,且高度依赖AWS服务。
对于我来说更倾向于使用传统数据库的向量扩展,比如这里我使用Redis+RedisSearch来实现向量库。
因为企业级项目很多时候已经维护了一个大的Redis集群,而且很多云厂商也暂时不支持专用向量数据库。
二、代码实战
一)技术架构
分为导入和搜索两个流程。
导入过程:
把我们需要导入的一篮子图片集通过
Clip转成向量,然后把向量导入Redis存储起来。搜索过程:
搜索过程也是类似,把我们想要搜索的图片和文本同样使用
Clip使用也进行向量化,然后去Redis中进行向量检索,就实现图片搜索引擎啦!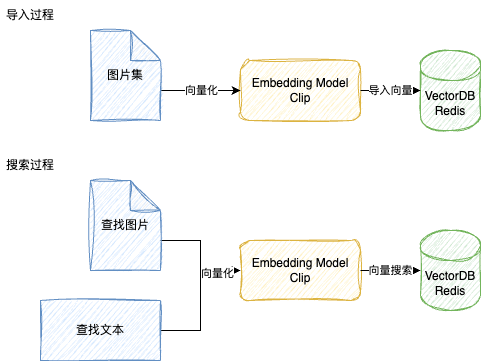
二)准备图片
既然是图片搜索引擎,当然得有海量图片了。处理多媒体文件的神器登场:FFmpeg
1、安装ffmpeg
mac系统安装更简单,直接用homebrew安装
其他操作系统(linux,window)安装也比较简单,可以直接去官网下载。
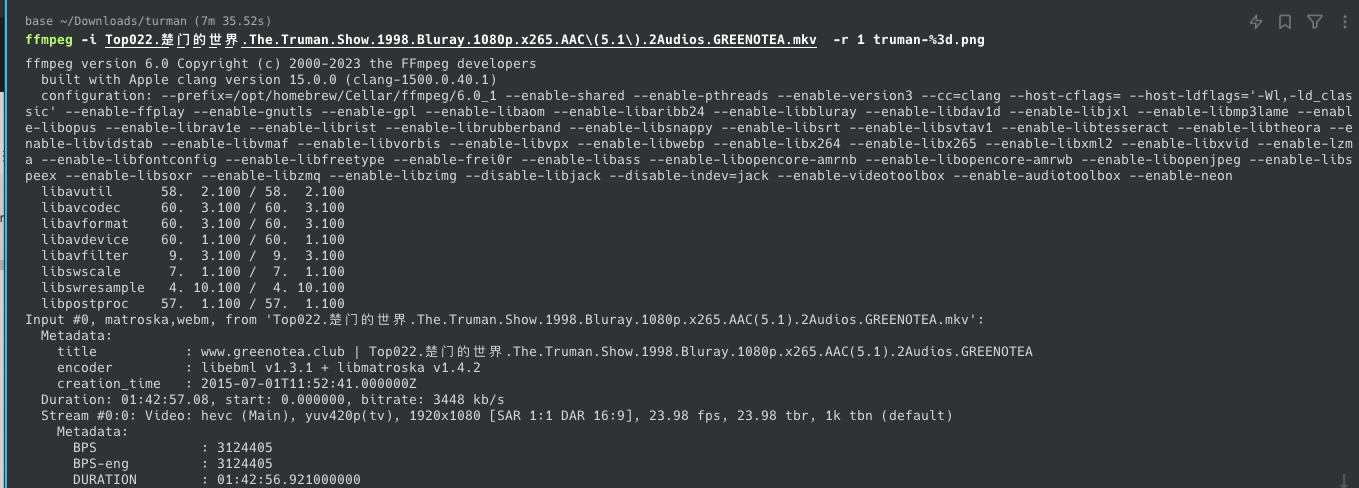
2、生成图片
我选了个自己比较喜欢的电影《楚门的世界》,把视频文件进行每秒抽帧来生成图片素材。
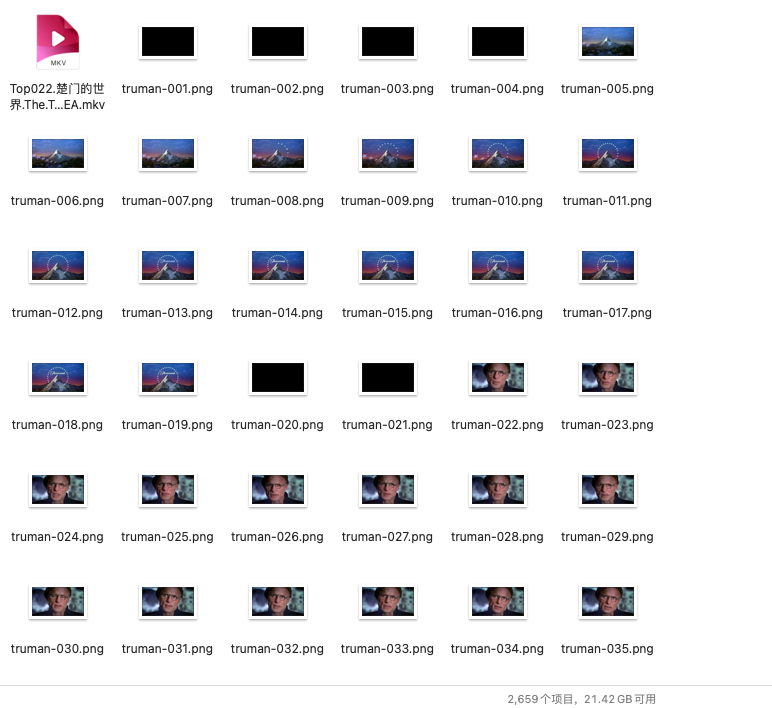
经过一段时间的cpu飞速运转,得到了2000多张图片
三)环境准备
1、安装Python
安装python的可以直接去官网https://www.python.org/downloads/
英文不太好可以去看这个国人出的菜鸟教程https://www.runoob.com/python3/python3-install.html
2、安装redis
推荐使用docker安装redis,我们选用了7.2.0的新版本redis
docker-compose文件参考:
启动redis

四)图片向量化
1、导入向量库
指定我们图片的目录,把每张图片使用clip进行向量化,然后存入redis向量库中。
导入完成后可以看到,我们的2000多张图片都作为key转存储到redis中了。
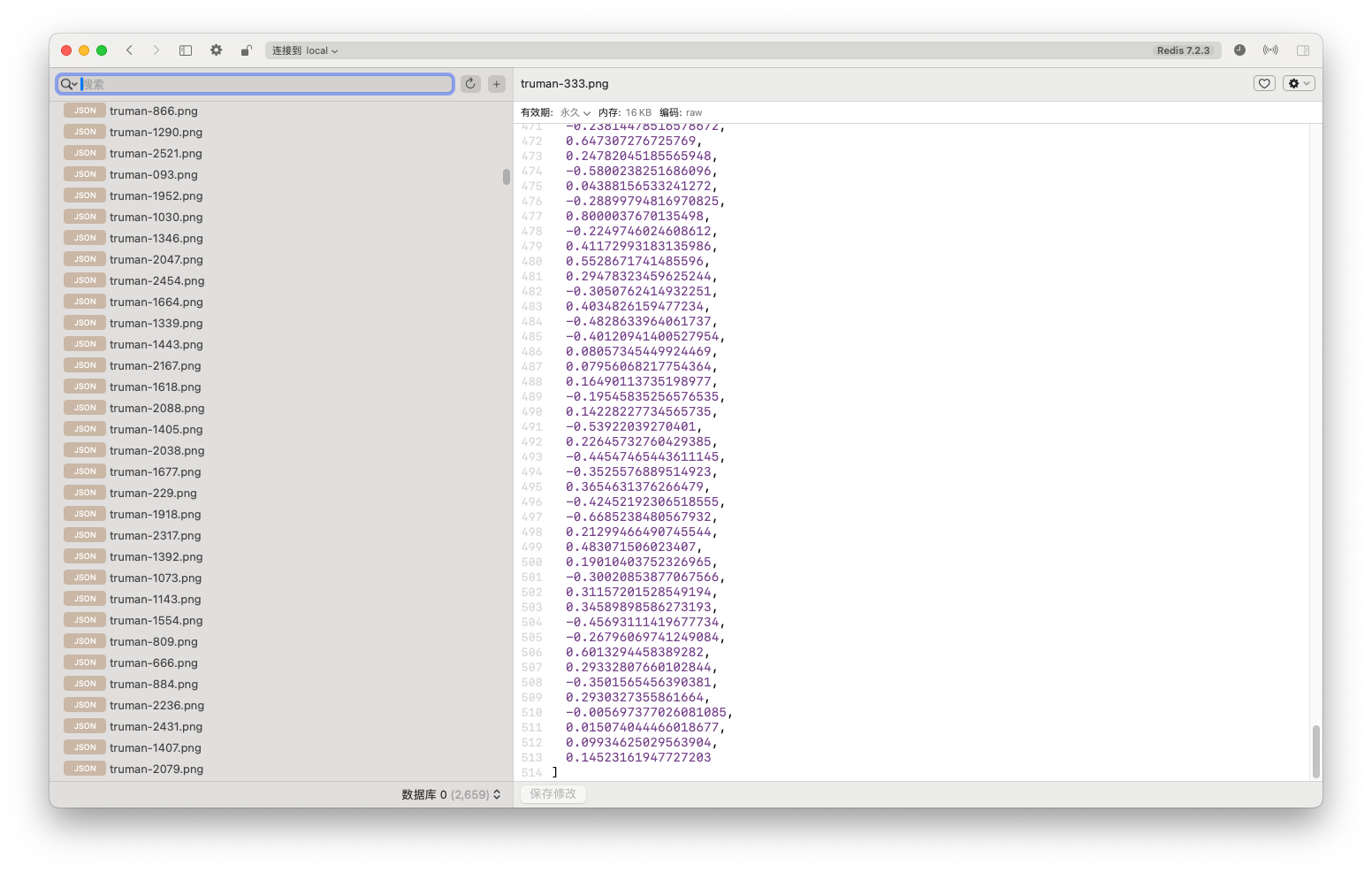
我们看到每个key的value都是512位的浮点数组,512位就代表我们向量的维度是512维,维度越高代表着存储的特征越多。

2、构建向量索引
使用RedisSearch来把上面的向量构建索引。
五)以图搜图
激动人心的时刻到了,终于可以看到结果了!~
运行下方代码
我们搜索跟这张图类似的5张图片。
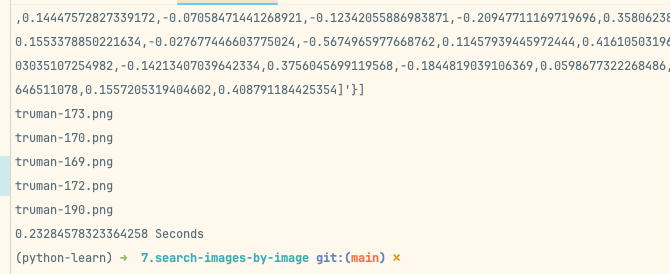
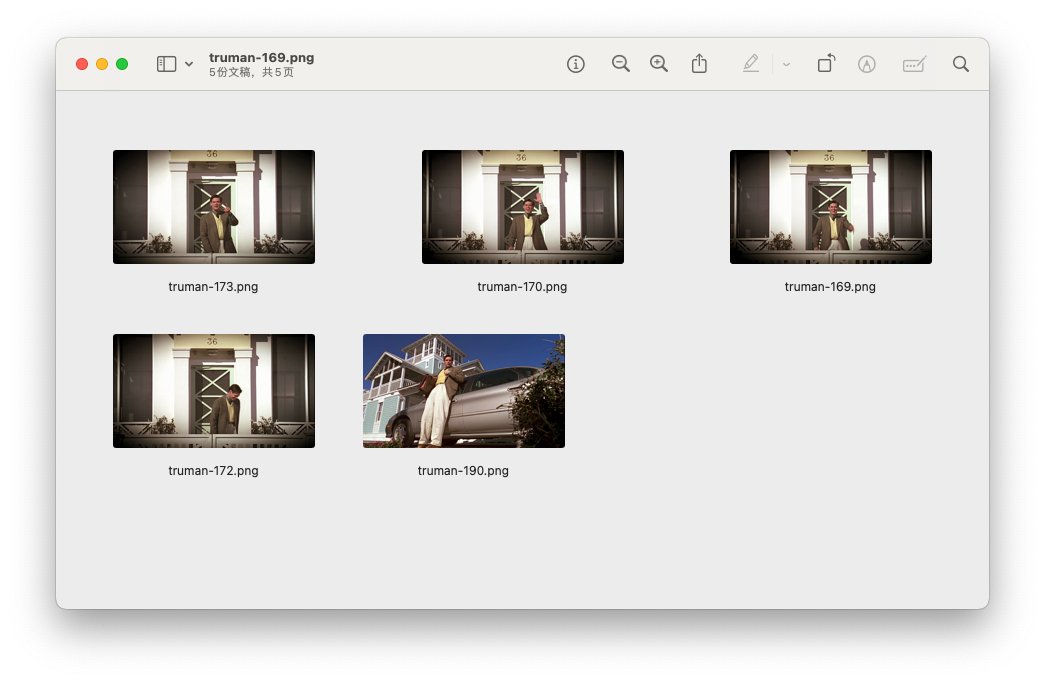
首先原图是被搜出来了,然后搜出特征相似的图片了,感觉还不错的样子。
六)文字识图
clip还具有识图能力,可以算出给出词数组和图片相似度的概率密度。这里给他一个图片和一组单词
['dog', 'cat', 'night', 'astronaut', 'man', 'smiling', 'wave', 'smiling man wave'],让他给我算算。
结果smiling man wave(微笑的男人挥手)这个词的概率最大,确实跟我们图片的特征一致。
七)文字搜图
把文字做Embedding,去redis做向量检索就可以实现文章搜图的能力了。
这是搜索
smiling man的top5结果,确实是可以实现通过我们的语义进行搜索图片了!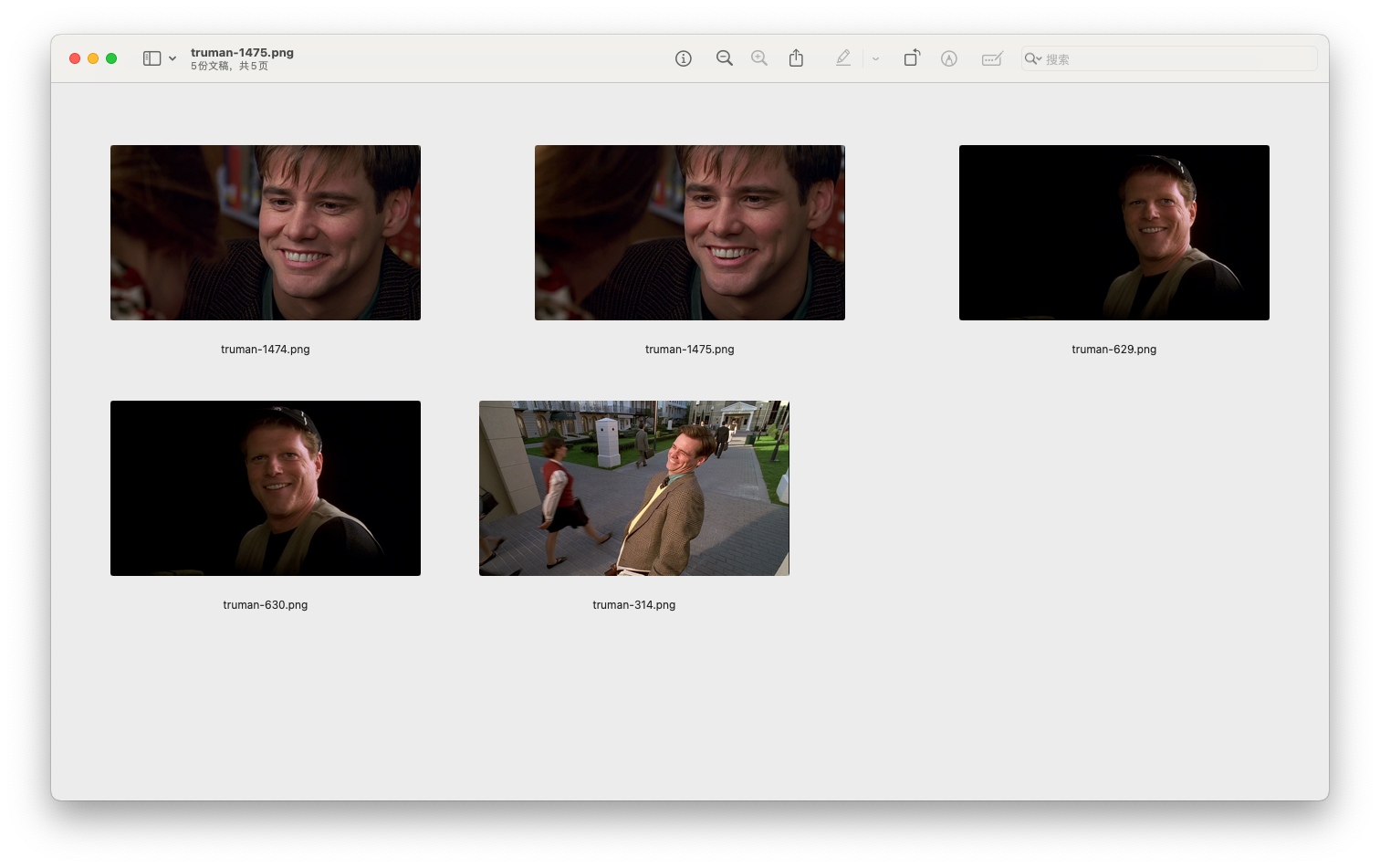
再搜索
Say hello,也搜到了上面大笑打招呼的图片。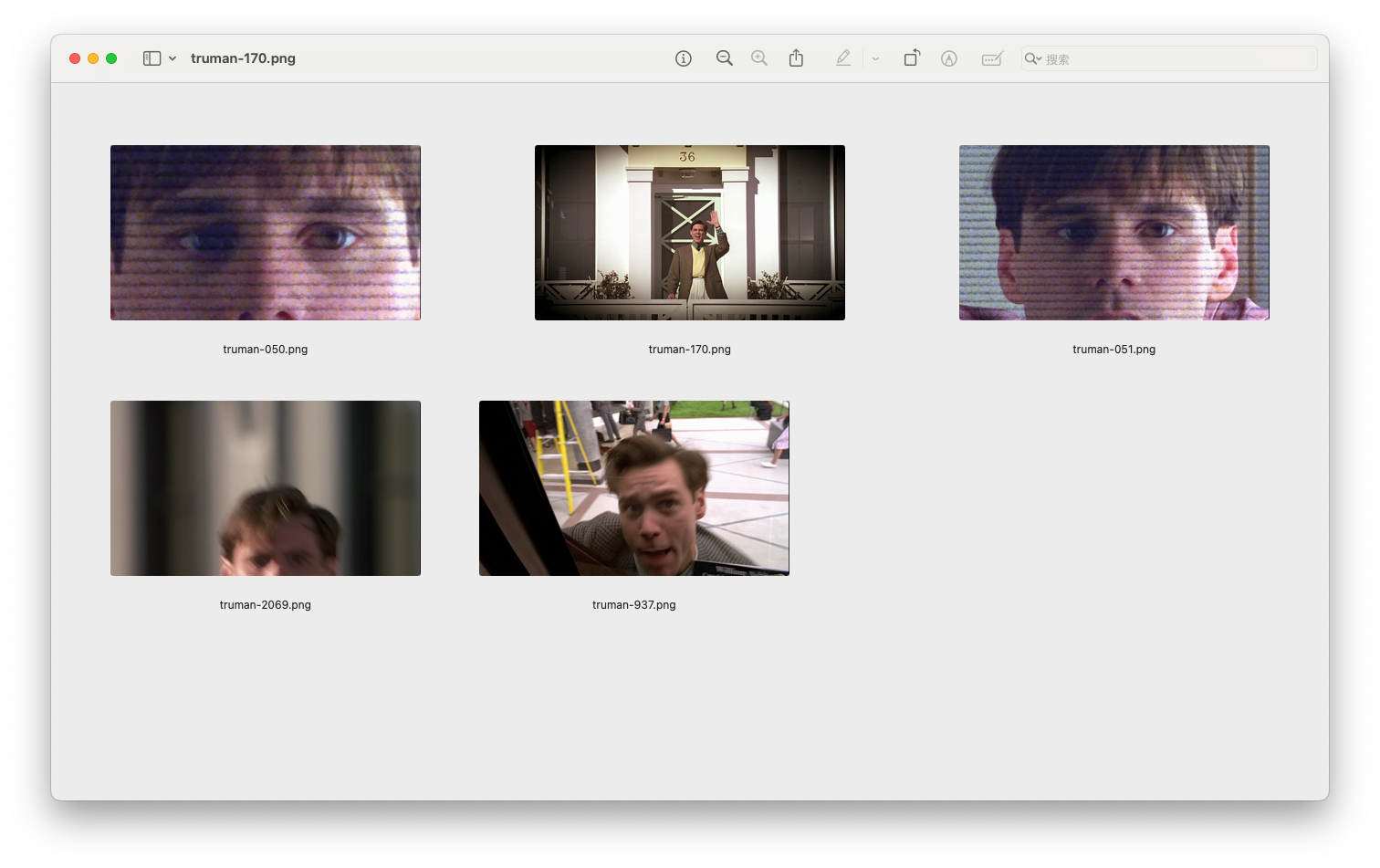
三、总结
AI的快速发展可以让我们一个不是机器学习专业的也可以用模型做出一个有趣又有一些价值的AI项目。
下面是我的几个启发
1.学习AI从调接口开始,但不要只是调接口。
调OPENAI的API是比较简单,上手快,可以快速做出一些案例。但不要把思维框在调接口里,Huggingface上还有大量好玩的模型,也不一定需要gpu,cpu上也可以玩起来,要多上手尝试,其实没想象中那么难。
2.产品化
我们这里只是投喂了一部电影,当我们投喂大量电影,并做出ui界面给普通用户使用,这里还是有很大商业价值的。
整理自全栈开发大佬苏洋:https://github.com/soulteary
联系我
AIGC交流群:

微信:
添加微信回复「加群」,拉你入交流群

- 作者:鹤涵
- 链接:https://www.hehanwang.com/article/simple-image-search-engine
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。











